TIL_20220207
CKA Practice with KodeKloud
Maintenance - OS Upgrades
keywords: #drain #cordon #uncordon
drain은 노드 관리를 위해 특정 노드에 있는 파드들을 다른 노드로 이동시키는 명령이다. 새로운 파드가 더이상 해당 노드에 스케줄링되지 않도록 설정하고, 기존에 실행중이던 파드들을 다른 노드들로 이동시킨다. 만약 단일 노드라면 파드들은 스케줄링되지 못하고 Pending 상태로 남아있게 된다. 해당 노드에 데몬셋으로 실행된 파드가 있으면 drain에 실패한다. 데몬셋으로 실행된 파드들은 삭제해도 데몬셋이 즉시 다시 실행시키기 때문이다. 이를 무시하고 진행하려면 --ignore-daemonsets 옵션을 준다.
kubectl drain $NODENAME --ignore-daemonsets
해당 노드에 파드들을 다시 스케줄링하고 싶다면, uncordon 명령을 사용하여 활성화시킨다.
kubectl uncordon $NODENAME
기존에 해당 노드에서 실행되던 파드들은 다른 노드에서 실행되고 있으므로 해당 노드가 다시 활성화된다 하더라도 복귀하지 않는다. 다만, 데몬셋으로 실행되었던 파드들은 해당 노드의 활성화와 동시에 데몬셋이 재시작되면서 원래대로 복귀한다.
replicaset이 없는 싱글 파드는 drain 명령으로 다른 노드로 이동시킬 수 없다. 이때에는 --force 옵션을 주어 강제로 삭제한다. 이 경우에는 해당 파드는 클러스터에서 영원히 사라지게 된다.
kubectl drain $NODENAME --force
해당 싱글 파드가 사라져서는 안될 때에는 drain 명령이 아닌 cordon 명령을 사용한다. cordon 명령을 사용하면 해당 노드에서 실행되던 파드들은 유지하고 더 이상 스케줄링하지 않는다.
kubectl cordon $NODENAME
Maintenance - Cluster upgrade process
keywords: #taints #kubeadm #kubelet
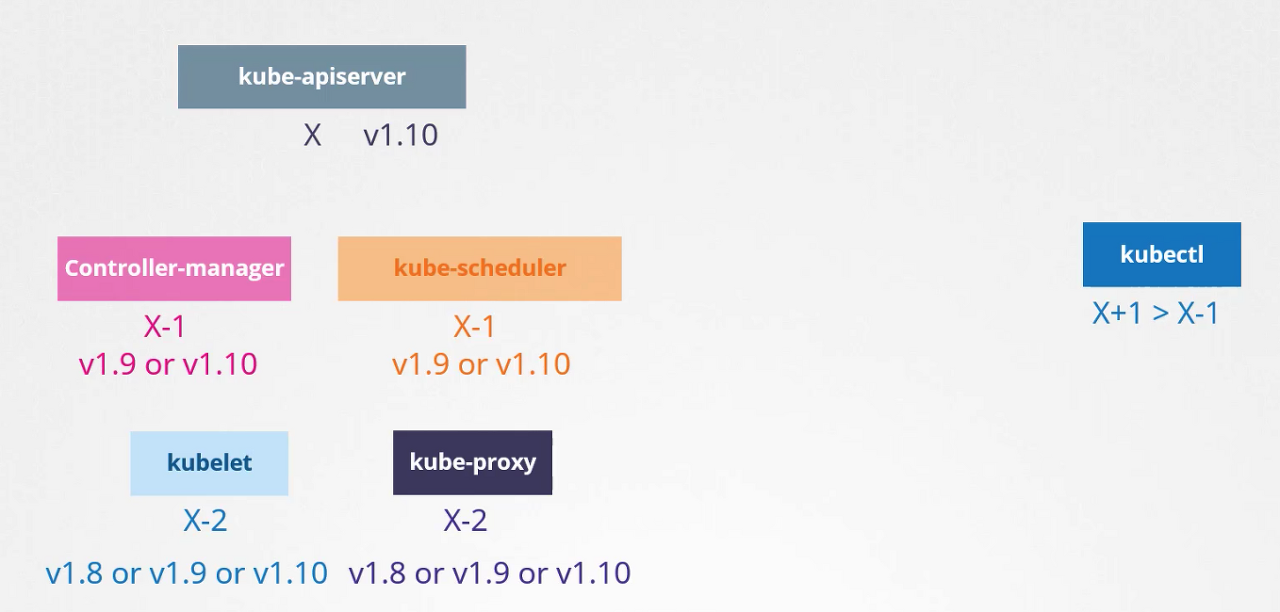
쿠버네티스의 버전은 kube-apiserver기준으로 정해진다.
- controller-manager, kube-scheduler 버전은 메이저버전을 기준으로 1단계 아래까지만 허용한다.
- kubelet, kube-proxy 버전은 2단계 아래까지만 허용한다.
- kubectl은 위아래로 1단계까지 허용한다.
워크로드를 호스팅할 수 있는 노드의 갯수를 알아보기 위해서는 taints 되어있는 노드가 있는지 확인한다.
kubectl describe nodes | grep -i taints
다운타임을 최소화하기 위해서는 클러스터를 한 번에 한 노드씩 업그레이드하면서 워크로드를 다른 노드로 이동한다. 업그레이드하려는 노드를 drain시킨 후 업그레이드를 진행한다. 업그레이드는 메이저버전의 경우 1단계씩 진행해야 한다. (1.17 -> 1.18 가능, 1.17 -> 1.20 불가능)
kubectl drain $NODENAME --ignore-daemonsets --force
현재 kubeadm에서 업그레이드가 가능한 버전이 무엇인지 알아본다.
kubeadm upgrade plan
노드의 업그레이드 방법과 순서는 다음과 같다.
# 업그레이드하려는 노드 비활성화
kubectl drain $NODENAME --ignore-daemonsets --force
# 업그레이드하려는 노드에 접속
ssh $NODENAME
# 모든 라이브러리 업데이트
apt update
# kubeadm 업그레이드 버전 다운로드
apt install -y kubeadm=<다운로드할 버전>
# 해당 노드에 대한 업그레이드 버전 적용
kubeadm upgrade apply v<다운로드한 버전>
# kubelet 업그레이드 버전 다운로드
apt install -y kubelet=<다운로드할 버전>
# kubelet 재시작을 통한 업그레이드 버전 적용
systemctl restart kubelet
# 업그레이드한 노드 활성화
kubectl uncordon $NODENAME
Maintenance - Backup and restore methods
keywords: #etcd #snapshot

백업할 때에는 불상사를 막기위해 위의 두 요소 모두 백업해주어야 한다.
- 현재 띄워져있는 모든 리소스를 yaml파일로 추출하여 저장한다.
kubectl get all --all-namespaces -o yaml > all-deploy-services.yaml
- etcd를 백업하고 복구한다.
# etcd 정보 확인
kubectl describe pod etcd -n kube-system
# etcd 스냅샷 저장
ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=<trusted-ca-file> \
--cert=<cert-file> \
--key=<key-file> \
snapshot save <backup-file-location>
# 스냅샷 상태 확인
ETCDCTL_API=3 etcdctl snapshot status <backup-file>
# etcd 복구
ETCDCTL_API=3 etcdctl \
--data-dir /var/lib/etcd-from-backup \
snapshot restore snapshot.db
# /etc/kubernetes/manifests/etcd.yaml 파일의 볼륨 호스트패스를 복구 경로로 변경
volumes:
- hostPath:
path: /var/lib/etcd -> /var/lib/etcd-from-backup
type: DirectoryOrCreate
name: etcd-data
# 자동으로 etcd 파드가 재시작된다. 그렇지 않으면, 기존 파드를 삭제한다.